3.5 KiB
Merry-Go-Round sync (Erigon design)
Initial discussion here: https://ethresear.ch/t/merry-go-round-sync/7158
Participants
We divide participants into two types: seeders and leechers. Seeders are the ones who have the full copy of the current Ethereum state, and they also keep updating it as new blocks appear. Leechers are the ones that join the Merry-Go-Round network to either acquire the full copy of the state, or "sift" through it to acquire some part of the state (this is what some "Stateless" node might like to do in the beginning).
Syncing cycles
The process of syncing happens in cycles. During each cycle, all participants attempt to distribute the entire content of the Ethereum state to each other. Therefore the duration of one cycle for the Ethereum mainnet is likely to be some hours. Cycle is divided into ticks. For convenience, we can say that each ticks starts after the mining of certain block, and lasts for some predetermined amount of time, let's say, 30 seconds. This definition means that the ticks will often overlap, but not always, as shown on the picture below.
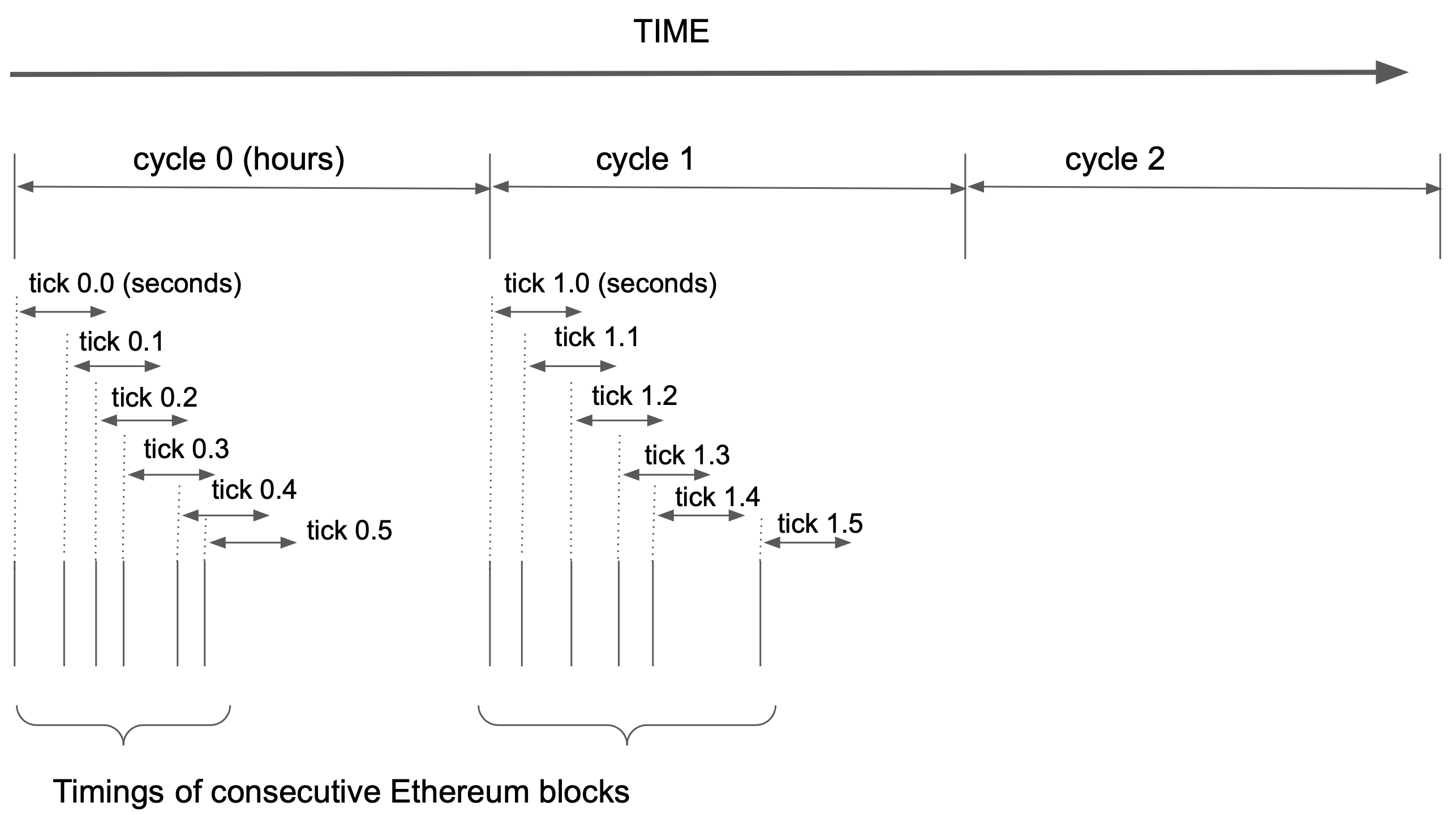
If chain reorgs occur, and the timings of recent Ethereum blocks change as a result, we can accept these rules to prevent the reorgs to be used to disrupt the sync. Imagine the tick started at block A (height H), and then due to reorg, block A was replaced by block B (also height H).
-
If timestamp(B) < timestamp(A), the tick does not shorten, but proceeds until timestamp(A) + tick_duration.
-
If timestamp(B) >= timestamp(A), the tick gets extended to proceed until timestamp(B) + tick_duration.
As one would guess, we try to distribute the entire Ethereum state into as many pieces as many ticks there are in one cycle. Each piece would be exchanged over the duration of one tick. Obviously, we would like to make the distribution as even as possible. Therefore, there is still a concern about situations when the blocks are coming in quick succession, and the ticks corresponding to those blocks would largely overlap.
Sync schedule
When we split the entire Ethereum state into pieces and plan to exchange each piece during one tick, we are creating a sync schedule. Sync schedule is a mapping from the tick number (which can be derived from the block number) to the piece of state. These pieces need to be efficient to extract from the State Database (for a seeder), and add to the State Database (for a leecher). Probably the most convenient way of specifying such a piece of state is a pair of bounds - lower bound and upper bound. Each of the bounds would correspond to either Keccak256 hash of an address, or to a combination of Keccak256 hash of an address, and Keccak256 hash of a storage location in some contract. In other words, there could be four types of specification for a piece of state:
[ keccak256(address1); keccak256(address2) )[ keccak256(address1), keccak256(location1); keccak256(address2) )[ keccak256(address1); keccak256(address2), keccak256(location2) )[ keccak256(address1), keccak256(location1); keccak256(address2), keccak256(location2) )
In the last type, addresses address1 and address2 may mean the same address. If they mean different addresses, then location1 and location2 may mean the same locations.
How will seeders produce sync schedule
Seeders should have the ability to generate the sync schedule by the virtue of having the entire Ethereum state available. No extra coordination should be necessary.