* header download docs * Continue * Fix * More picture and text * Push * More doc * More docs * First version of the doc
15 KiB
Block header download process
This process is a collection of data structures and algorithms to perform the task of obtaining a consistent and verified header chain from peers over the network.
Data structures
All data structures, except for the files, are kept in operating memory (RAM), and do not survive an interruption, a crash, or a powerdown. Therefore,
there is RECOVER algorithm described later, which initialises all transitent data structures from the files.
The buffer
It is an append-only collection of headers, without any extra indices. The buffer is of a limited configurable size. Apart from block headers, the buffer may contain another type of entries that we will call "tombstones". The tombstones mark certain block hashes as undesirable (usually because they are part of of a fake chain produced for the purpose of frustrating the download process). Like ordinary header entries, the tombstones contain block height information, so that they can be sorted together with the headers. As will be mentioned later, this sorting is performed when the buffer is full and needs to be flushed into a file. Presence of tombstones allows skipping all the descendant headers of any tombstone, and not persisting them into the files. This happens when an undesirable header is detected before its decendants were flushed into a file. Otherwise, it is possible that some undesirable headers will get into the files, and they will need to be ignored when the files are getting processed and entries committed to the database.
The files
Once the buffer reaches its maximum size (such that adding anorher header would cause the buffer to exceed its size limit), the entries in the buffer are sorted by the block height (and in the case of ties, by the block hash), in ascending order. Once sorted, the content of the buffer is flushed into a new file, and the buffer is cleared. The files are supposed to persist in the event of an interruption, a crash, or a powerdown. The files are deleted once the block headers have been successfully committed to the database, or they can be deleted manually in case of a corruption.
Bad headers
Set of block hashes that are known to correspond to invalid or prohibited block headers. The bad headers set can be initialised with hard-coded values. Not every invalid header needs to be added to the bad headers set. If the invalidity of a block header can be found just by examining at the header itself (for example, malformed structure, excessive size, wrong Proof Of Work), such block header must not be added to the bad headers set. Only if the evidence of the invalidity is not trivial to obtain, should a block header be added. For example, if a block header has valid Proof Of Work, but it is a part of a header chain that leads to a wrong genesis block. Another example is a blocl header with correct Proof Of Work, but incorrect State Root hash. Newly found bad block headers need to be immediately written to the database, because the cost of discovering their invalidity again needs to be avoided.
Chain segment (anchors)
At any point in time, the headers that have been downloaded and placed into the buffer or into one of the files, can be viewed as a collection of chain segments like this:
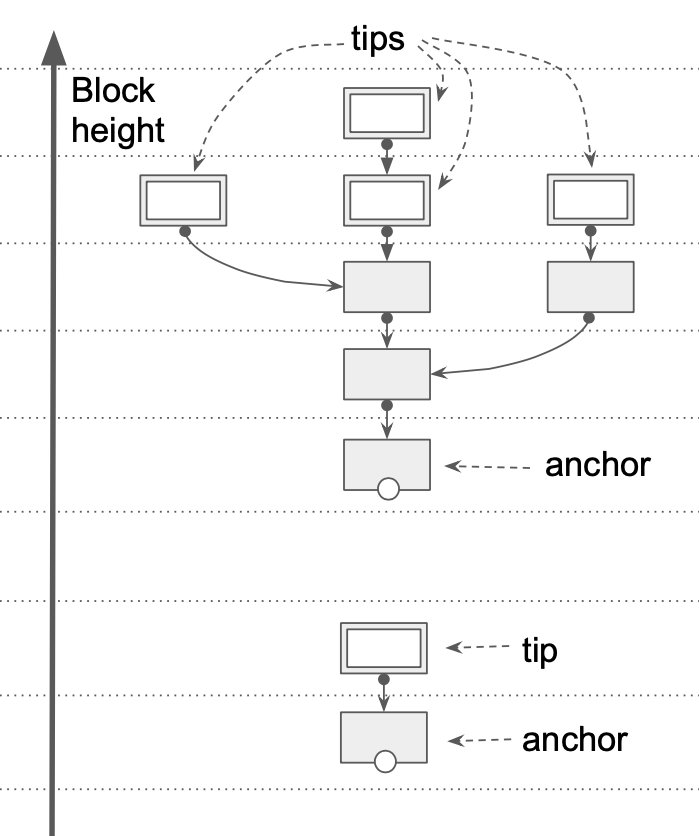
The reason why we may need to maintain multiple chain segments instead of just one, is this potential optimisation. If we have some hindsight knowledge
about the header chain that is being downloaded, we can hard-code the hashes of block headers at some intermediate block heights. For example, at every
height which is multiple of 4096. Assuming that the maximum height is on the order of tens of millions, we only need to hard-code around a thousand
32-byte values (block hash), together with total difficulty number (maximum 32 byte), which is trivial. Having these hard-coded anchors, we can
download different chain segments from different peers to better utilise the network connectivity.
Each segment has exactly one anchor. Every anchor maintains an integer attribute powDepth, meaning how "deep" after this anchor the ancestral block headers
need their Proof Of Work verified. Value 0 means that there is no need to verify Proof Of Work on any ancestral block headers. All hard-coded anchors come
with powDepth=0. Other anchors (created by announced blocks or block hashes), start with powDepth equal to some configured value (for example, 65536,
which is equivalent to rought 16 days of block time), and every time the chain segement is extended by moving its anchor "down", the powDepth is also
decreased by the height of the extension.
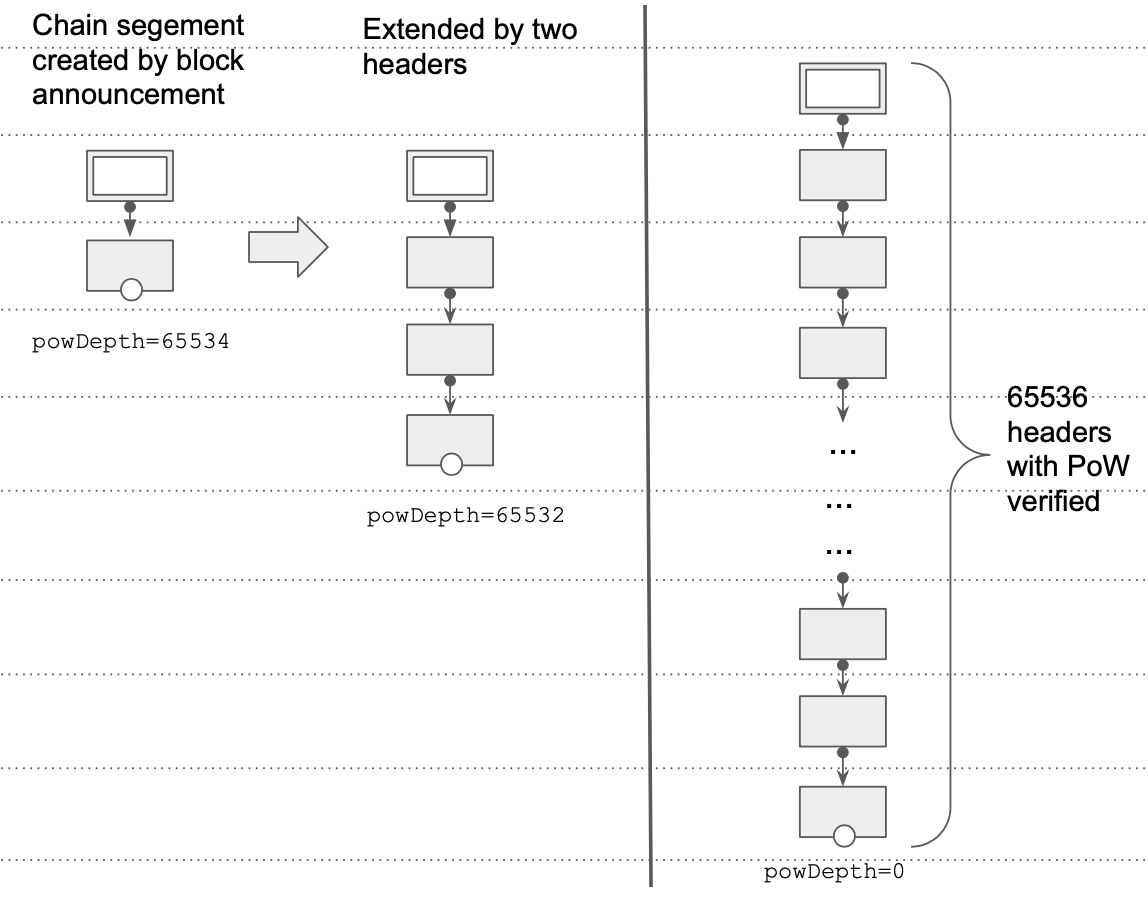
Eventually, the growing chain segement can reach the configured size, at which point the powDepth attribute of its anchor will drop to 0, and no
further Proof Of Work verification on the ancestors will be performed. Another possibility is that the anchor will match with a tip of another chain
segment, the chain segments will merge, and the anchor simply disappears, superseeded by the anchor of another chain segment.
There is also a potential optimisation, whereby the extension of a chain segment from the tip shall also decrease the powDepth value of its anchor.
However, we currently leave this for future editions.
Another attribute of an anchor is totalDifficulty. Total difficulty is the sum of all difficulties of headers starting from this anchor, all the
way to the genesis, including the anchor itself. The total difficulty can only be obtained for the segments that in some ways originated from a
hard-coded anchor. The genesis is also considered a hard-coded anchor. The anchors created from block announcements or block hash
announcements, have their totalDifficulty equal to 0, meaning that it is currently impossible to calculate the total difficulty given the available information.
Since any chain segment contains exactly one anchor, the anchor hash can be conveniently used as an identifier for the chain segment. Other important parts
of a chain segments are its tips. Therefore, an anchor has another attribute, tips, which is a collection of block hashes currently belonging to the
chain segment's tips. This collection allows efficiently iterating over the tips of a certain chain segment, for example, to update the total
difficulties of the tips when the anchor changes.
When a chain segment gets appended to an existing anchor, there are a few conditions that need to be met. Firstly, the parentHash of the anchor header
needs to match the hash of the attaching tip. Secondly, the difficulty calculation formula for the anchor yields the anchor's difficulty. In Ethereum, difficulty of a child block header is calculated from various attributes of that child block header (timestamp) and the parent block header
(timestamp, difficulty, blockHeight). Therefore, anchors need to have two other attributes, difficulty and timestamp, so that the correctness
of the calculating difficulty from its parent header can be verified.
To conclude, the anchors data structure (which is a part of "the chain segments" data structure) is a mapping of anchor parentHashes (not hashes of
anchors themsevles) to a collection of objects with attributes powDepth, totalDifficulty, tips, difficulty, and timestamp. We are talking
about collection of objects rather than objects because there may be multiple anchor headers having the same value of Parent Hash.
Chain segment (tips)
A chain segment can contain any number of headers, all connected to one another via the value of their ParentHash attribute, and, ultimately,
such tree of headers is connected to the anchor of that chain segment. Some headers in a chain segment are selected as the tips of that chain segment.
Description of how the headers are the headers are selected to be the tips requires the definition of cumulative difficulty. Every tip (once selected)
has some attributes associated with it. Firstly, the anchorParent attribute, which is the ParentHash of the anchor that this tip is (transitively)
connected to (in other words, the tip is in the "progeny", or in the "decendants" of that anchor). The anchorParent attribute of a tip can be viewed
as the inverse of the anchor's tips attribute, and both need to be updated at the same time, when the anchor or one of the tips of a chain segment changes.
Secondly, the cumulativeDifficulty attribute of a tip stores the sum of difficulties of all headers starting from the tip all the way down
(and including) the anchor. The cumulative difficulty, combined with the anchor's totalDifficulty (minus the the difficulty of the anchor so
that it is not counted twice), provides a way of calculating the total difficulty of a tip.
A subset of headers in a chain segment is selected to be the tips of that segment. The necessary (bit not sufficient) requirement for a header
to be a tip is that it has cumulative difficulty no lower than cumulative difficulty of any non-tip in that segment. In other words, tips are
the headers wotj the largest cumulative difficulties in their chain segment.
To ensure resilience against potential resource exhaustion due to faults or deliberate attacks, we would liketo limit the number of tips being
tracked at any given time, and, by extension, the number of chain segments being maintained. For this purpose, we place almost all currently
tracked tips from all chain segments into a sorted mapping, sorted by cumulative difficulty. The tips whose hashes coincide with any of the hard-coded
anchors, are exempt from the limiting, and therefore, are not placed into the sorted mapping.
This sorted mapping is used whenever the number of tracked tips is about to exceed the (configurable) limit. Entries with the lowest cumulative
difficulties are removed from the mapping, as well as from the tips data structure.
The tips data structure (which is a part of "the chain segments" data structure) is a mapping of tip hashes to objects with the attributes
anchorParent, cumulativeDifficulty, timestamp, difficulty, blockHeight.
We will call the sorted mapping of cumulative difficulties to tip hashes "the tip limited data structure.
Working chain segments
The anchors, the tips, and the tip limiter describe a collection of chain segements. We will this collection "working chain segments" for the future reference in the description of the algorithms.
Principles and invariants
When a new anchor can be created
A new chain segment can only be introduced in the following 3 ways and according to specified conditions:
- Hard-coded anchors
- Anchors recovered from the files during the restrt after an interruption, a crash, or a powerdown
- Block announced by a peer, or a block header received from a peer, if the Proof Of Work is valid, and if the timestamp of such block or block header is withing a configured range from the current time measured locally. In other words, with a timestamp not too far in the past and not too far in the future.
The condition on the block header timestamp in the point (3) is required to prevent a potential malicious peer from being able to reuse the same pre-generated fake chain segements again and again over a long period of time. The tips of such pre-generated fake chain segments would need large cumulative difficulty to be able to force genuine tips from the tip limiter. But even if they are generated at a cost of significant work (to pass Proof Of Work verification), they will only be useful for a limited period of time. According to the limitation in the point (3), we will refuse to create a new anchor and therefore ignore any of its ancestral headers (see the next principle below).
When a chain segment can be processed
A chain segment constructed from a message received from a peer, can only be appended to an existing anchor of some "working chain segment. In other words, we would only allow appending new ancestral chain segements to existing children (or "progeny"). Part of the new chain segment that ends up "above" the attachment point is discarded, as shown on the diagram below. If there is no anchor to which any header in the new segment can be appended, the entire new chain segment is discarded.
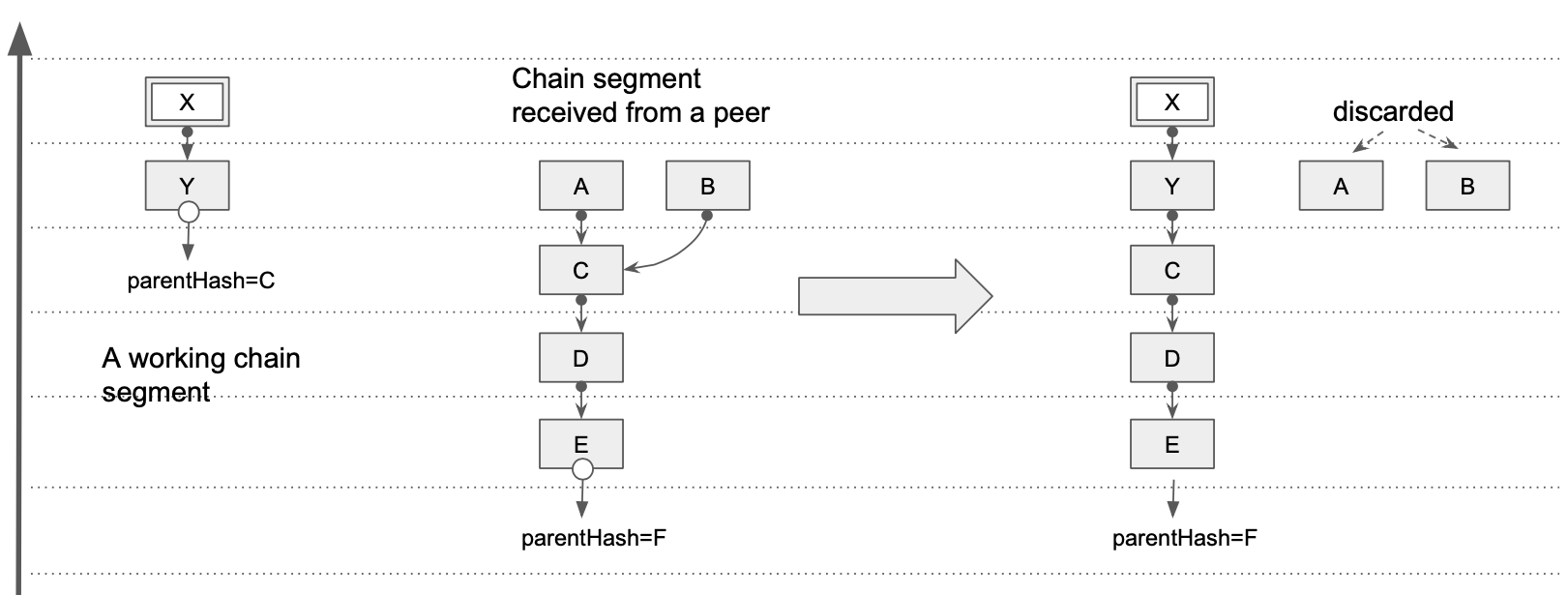
Note that this restriction is applied even before any Proof Of Work verification is performed on the received headers. The anchor to which the
received chain segment is getting appended, determines whether, and for how many headers in the segment the Proof Of Work verificatin needs to
be done (powDepth attribute). As mentioned previously, the new anchor's attribute powDepth is calculated from the existing anchor's
powDepth and the length of the part of the new chain segment that had been appended.
Invariants (TODO)
Algorithms
Currently, the algorithms are just listed without much explanation. Detailed explanation will be added after Proof Of Concept.
Handle BlockHeadersMsg
Input: BlockHeaderMsg + peer handle. Output: chain segment or penalty for the peer handle
Handle NewBlockMsg
Input: NewBlockMsg + peer handle. Output: chain segment or penalty for the peer handle
Prepend
Input: chain segment + peer handle. Output: updated structures (modified working chain segments) or "no prepend point foind", or penalty for the handle (tombstone creation)
We do not allow prepending to the hard-coded tips (therefore tips need an extra boolean attribute noPrepend)
Append
Input: chain segment + peer handle. Output: updated structures (modified working chain segments) or "no append point found", or penalty for the handle (tombstone creation)
Create anchor
Input: chain segment + peer handle. Output: updated structures (new working chain segment) or "anchor too far in the future" or "anchor too far in the past", or penalty for the peer (e.g. invalid PoW)
Recover from files
Input: the files. Output: working chain segments
Request more headers
Input: working chain segments. Output: GetBlockHeadersMsg requests For this algorithm we will require an extra data structure, which is a priority queue containing achor parent hashes, prioritising by latest request time. This is to ensure we can easily handle time outs and grow all chain segements evenly (in round-robin fashion).
Handle NewBlockHashMsg
Input: NewBlockHashMsg + peer handle. Output: GetBlockHeadersMsg request.
Flush the buffer
Input: The buffer. Output: the files
Initiate staged sync
Detect when to start the staged sync. Whenever a new tip is added, we check that its attribute anchorParent is equal to pre-configured value 0x00..00 for sync from genesis, or the hash of the last block header we have processed in the stage 1 of the staged sync. If this condition is satisfied, we take
the attribute totalDifficulty of the tip and compare it to a variable highestTotalDifficulty (initialised to zero in the beginning). If the tip's
totalDifficulty is higher than highestTotalDifficulty, then we set highestTotalDifficulty to the new value, and initiate the staged sync from
the tip's anchor to the tip